(Epidemiology, a Greek term meaning “what is upon the people”)
Traditional thoughts of the self-insured employer
What is the catalyst that drives an employer to shift their risk management strategy from a fully insured employee health plan to a self-insured health plan? In theory, it is probably due to the potential for saving money. However, where does the money savings come from? Initially, the savings will come from the reduction in administrative services payments that are associated with fully insured health plans. By evolving to a self-insured plan, an employer will immediately reduce the administrative fees that carriers charge for fully insured health plans. What then? How is an employer going to build a sustainable strategy for continued savings?
The set of directions that an employer has to rely upon are virtually non-existent when it comes to managing a self-insured population. In general, the employer will evolve along the following path:
- The first year: Adopt a self-insured employer-sponsored health plan and reduce administrative costs associated with the old fully insured plan.
- The second year: Impact savings by cost shifting to employees by way of the plan design and premium contributions.
- The third year: Evaluate the level of financial responsibility that the re-insurer is presently covering and consider raising or lowering the specific within the re-insurance coverage.
Do any of the aforementioned strategies sound familiar to you or your organization? Self-insuring is a goo economic strategy to reduce costs, if your strategy includes utilizing real-time empirical evidence to create risk management strategies. Planning sessions prior to reenrollment are not the same as developing true risk management strategies for population health management.
Empirical & epidemiological evidence for determining risk management strategies
Employers that adopt the strategy of evolving from fully insured health plans to self-insured health plans come from various industries. The common denominator of all of these employers is that they rely upon empirical evidence for managing their respective business units (e.g., production data, financial data, cost of goods analysis, competitive market intelligence data, etc.). These employers can effectively demonstrate their industry knowledge and knowledge of their own company with mountains of data. This data guides their decisions related to: how to make their company more profitable and efficient? Sound business decisions are not made on hunches or knee-jerk reactions; sound decisions are based on empirical logic.
Health care expense in Corporate America is one of the top five expenses experienced by most employers. Why not manage this potential loss center with empirically based logic to yield effective risk management solutions? The majority of self-insured employers do rely on empirical information for making decisions to some extent. Most self-insured employers utilize an actuary to project and predict the future financial expense associated with health care, and most employers receive aggregate reporting from their third party administrators to tell them what occurred over the past year. All of this information is then bundled together to make plan design decisions, negotiate with re-insurers and possibly to inform the benefits broker with information.
In reality, these are all administrative tasks that are preparing management hedge reports that will prepare the CFO within the company for next year’s budget and potential health plan expenditures. The use of this data is good, but it has really done nothing to fix the cost drivers within the population. The report generated by the actuary and by the third party administrator are normally aggregate reports. The actuary is probably utilizing age/gender predictive modeling that can account for about 28 percent of variance, whereas in reality, 72 percent will be random.
In addition, the aggregate predictive data generated by the actuary projects estimations for the spending of the group as a whole. Individual spending will be exogenous (outside of) and not be affected by the risk adjustment formulas developed by the actuary. The methodology utilized by actuaries is more of a mathematical model, rather than an epidemiological model that descriptively investigates the health of the individuals within a population. Aggregate models relate populations as homogenous groups (equally distributed risk); however, as we know, most groups have diverse areas of heterogeneity (randomly distributed risk) that can have adverse impact on overall spending for the group. The actuarial model is a risk adjustment technique, meaning the actuary uses available data to calculate the expected health expenditures of populations over a fixed interval of time (e.g., a month, quarter, or year). The employer then uses these projections to establish what form of subsidies will be necessary for the health plan to remain financially viable.
A better-informed solution can be derived by utilizing other available data sets to clearly identify what is driving costs and what are the potential risk management solutions. The first step in this task would be to develop a relational database that houses all of the various data sets that potentially yield evidence for future risk management solutions (see Figure 1).
Figure 1:
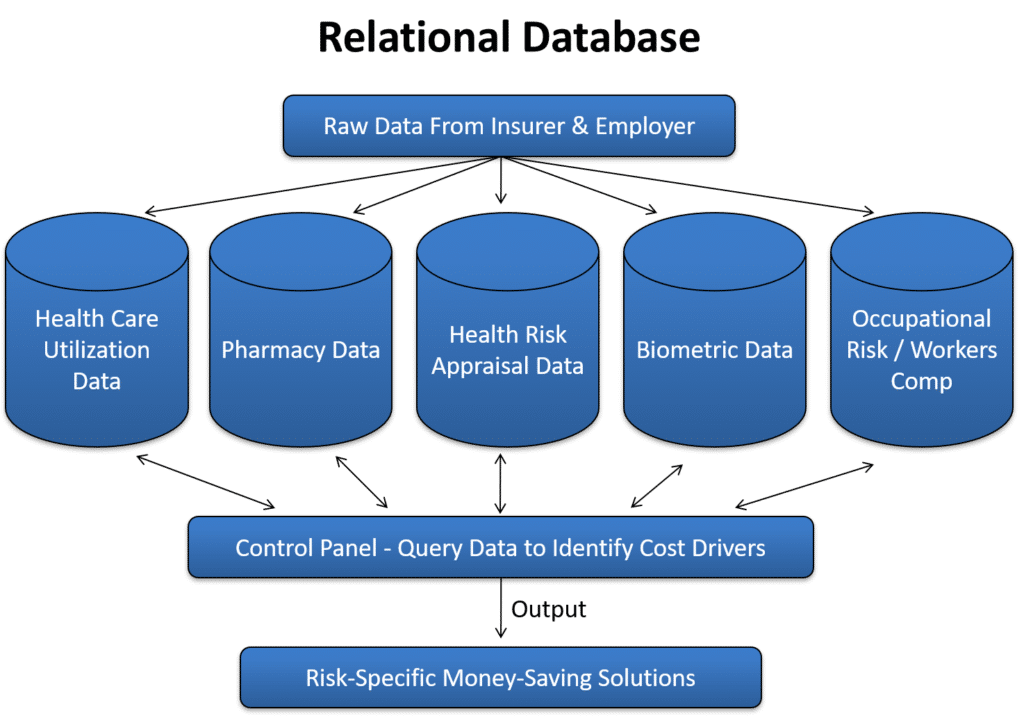
Relational Database
The ability to place all data sets into a relational database will increase the probability of discovering the cost drivers and determining a solution to reduce or mitigate the cost drivers. The relational database should be able to organize all of the various data sets into a reporting application that is simple to understand. The automated reporting could be run on a monthly or quarterly basis to yield real-time information to the internal risk manager within the selfinsured company.
An example table of contents for this reporting would include:
- Overall spending of Employee, Spouse, Dependent
- Gender-specific spending patterns
- Age-specific spending patterns
- Overall spending by diagnostic group
- Lifestyle-modifiable spending
- Chronic disease spending
- Expenditures on Prevention-related spending
- Chronic Disease-specific spending (e.g., heart disease, diabetes, hypertension, etc.)
- Outpatient spending, actual vs. normative
- Inpatient spending, actual vs. normative
- Emergency room spending, actual vs. normative
- Estimation of non-discovered risk factors by comparison to normative data
- Calculation of lost time associated with each diagnosis
- Overview of Pharmacy spending
- Estimation of value-based medication
- Summary of Cost drivers associated with the population
- Potential solutions to reduce cost drivers
- Projection of future spending without interventions
- Projection of future spending with interventions
Fitting the puzzle pieces together
If an employer is able to warehouse their various data sets into a relational database and have the ability to query the data along with standardized reporting, solutions can then be discovered for population health management. A properly designed relational database can make it easy for the employer to manage their various data sets real-time and create money-saving risk management solutions. The key is being able to connect the datasets with solutions.
Potential solutions would include:
- Disease Management programs
- Value-Based Plan Design
- General Wellness programming
- Implementing programs and incentives for individual preventative services
- Pre-employment screening
- Evidenced-based medicine with standardized Episodes of Care
- Implementing HEDIS standards
Plan design connecting health standard requirements to individual premium contribution
Essentially, the data will guide the decision-making process for risk management. Once the proper intervention has been selected, the relational database can measure the efficacy of the intervention on a pre/post basis. A fully functioning relational database should have the ability to segregate data sets and interventional groups in order to perform statistical procedures that will measure interventional efficacy. This allows the employer to place performance guarantees on the vendor that is selected to implement the chosen risk management service. It will also allow the employer to provide more accurate risk analytics to their re-insurer and validate risk mitigation within the population. Risk identification, mitigation, and proof of outcomes will yield cost savings. Controlling and understanding the data is the key to an effectively managed self-insured health plan.
About the Author

Richard Kersh is the founder and President of Human Factor Analytics, Inc., based in Russellville, Arkansas. Human Factor Analytics provides services to self-insured employers, benefits brokers, wellness providers and risk management organizations. Human Factor Analytics offers a web application to their clients for the storage,management and investigation of an employer’s various risk data sets, (i.e., health care utilization data, pharmacy data, health risk appraisal data, biometric data and workers compensation data). The web application allows the end user to search their various data sets and query the data through a relational database.
Richard was the founder and previous owner of Kersh Wellness Management, Inc. for approximately 20 years. During his time with Kersh, Richard designed and implemented wellness programs for Anheuser Busch Companies, Union Pacific Railroad, Harley Davidson, Bemis Corporations and several other U.S. Corporations. Richard developed various proprietary techniques for analyzing risk data elements, one of these methodologies was a statistical algorithm to measure the financial efficacy of a wellness intervention or risk intervention.